


 上一篇:
上一篇:  下一篇:
下一篇:  文章来自:
文章来自:  Tags:
Tags:  最新日志:
最新日志:
不错呦!smile@林凯西,确保“准备文件”中的几个文件都有安装,S...您好,看了您这篇帖子觉得很有帮助。但是有个问题想请...我的修改过了怎么还被恶意注册呢 @jjjjiiii 用PJ快9年了,主要是A...PJ3啊,貌似很少有人用PJ了,现在不是WP就是z...@332347365,我当时接入时错误码没有-10...楼主,ChkValue值应为-103是什么意思呢?...大哥 你最近能看到我发的信息,请跟我联系,我有个制...
云计算之路-博客园迁入阿里云故障一二三
编辑:dnawo 日期:2013-03-18
 引用内容
引用内容编者的话:这篇文章是由博客园官方博客发表的几篇文章整理而来,目的是学习下他们服务器发生问题后,怎么分析问题以及解决问题的方法。
一、奇怪的云服务器问题
其中一台的故事是这样的:
博客园找找看的后台服务(建索引,查找索引)很早就迁入阿里云的一台云服务器上,一直正常,Windows性能监视器中的Avg.Disk Read Queue Length在2左右。前几天,我们将它移到了另外一台云服务器上,找找看搜索速度变得很慢,在Windows性能监视器中监测到Avg.Disk Read Queue Length达到200多,竟然有百倍的差距。相同的程序,都是云服务器,却出现这么大的性能差距,而且速度慢的云服务器配置更好,我们拍脑袋就确定这台云服务器肯定有问题。
于是,我们向阿里云提交了工单,阿里云客服让我们停掉云服务器上面的应用,测试一下磁盘IO性能,如果磁盘确实存在问题,他们会把这台云服务器迁移至另外的集群上。而我们希望能先解决问题(把云服务器迁移至另外的集群),然后再测试磁盘IO性能;而阿里云客服希望先测试,确认有问题再迁移。于是,我们就用阿里云客服告诉我们的软件进行测试,开始的一个软件不支持云服务器(找不到硬盘);后来让我们用fio软件测试,由于对这个软件不熟悉,也没测试起来。我们准备另外安排时间研究一下这个软件,这个问题就这样搁置了。
另外一台的故事是这样的:
这台云服务器升级硬盘空间之后进行格式化时,一直显示正在格式化,等了很长时间也没反应,后来只能重启服务器,重新格式化,这次格式化成功。向阿里云反馈,得到的答复是当时这台云服务器的宿主机负载较大。之后,我们操作这台云服务器,总感觉反应有点迟钝,但也不知道问题出在哪。昨天,我们升级了这台云服务器的内存并进行重启(阿里云的云服务器升级内存或CPU都要重启,而且必须要通过管理控制台重启),竟然没启动起来,管理控制台显示状态为“启动中”,远程也连接不上。向阿里云提交工单,客服对这台云服务器进行了重启并成功启动起来。但操作时还是反应迟钝,出现两次这么大的问题,我们有些担心,不敢把它用于生产环境。于是,我们继续向阿里云提交工单,表示我们不敢继续使用这台云服务器;阿里云客服建议我们备份这台服务器上的数据,对系统盘和数据库进行重置。我们没听取这个建议。
两台加起来的故事:
我们冷静分析了一下这两台云服务器的故事。已经购买了13台云服务器,只有这2台出现了问题,而且这两台是最近购买的。又一查,这两台是同一天购买的,而且分配的IP很相近。很有可能是这两台云服务器在同一个集群上(云服务器是运行于集群上的虚拟机,而云服务商一般会有多个集群,这样可以分而治之),问题可能是因为这个集群的负载很高。
我们通过工单向阿里云提交了这个想法,然后接到阿里云客服的电话,说可以帮我们迁移到另一个集群上,需要我们先停运这两台云服务器。迁移大约15分钟。(我们猜测这个迁移也就是把虚拟机文件从一个地方复制到另一个地方,然后启动虚拟机)
我们停运这两台云服务器后,通知阿里云客服,5分钟不到就完成了迁移。迁移之后,那台反应迟钝的云服务器立即正常了。经过一段时间的观察,跑找找看后台服务的云服务器磁盘IO也正常了,Windows性能监视器中的Avg.Disk Read Queue Length保持在2左右。问题解决!
在迁移前遇到这样的问题的确让人担心,但是对于云计算如此复杂的平台,问题在所难免,只要弄清问题的真正原因并有相应的解决方法,就不是问题。另外,我们也希望出现问题时,云服务商首先应该考虑的是怎么让客户的服务器尽快恢复正常,然后再测试问题所在。
二、images.cnblogs.com响应速度慢的诡异问题
昨天,是我们迁入阿里云后经受高访问量考验的第一天,除图片站点(images.cnblogs.com)之外其他站点的访问速度表现都很不错。
images.cnblogs.com是我们之前存放上传图片的主要站点,现在用的是images.cnitblog.com。images.cnblogs.com部署在一台阿里云云服务器上,images.cnitblog.com 用的是又拍云(有CDN加速)。images.cnblogs.com没有使用又拍云是因为让人纠结的Url大小写的问题,详见之前的博文云计算之路:云存储的纠结。
昨天在上班时间的访问高峰期,images.cnblogs.com图片加载速度变得很慢,严重时变得奇慢无比。究竟慢到什么程度,请看下面的截图(这可是304 Not Modified的响应)。很多200响应会超时。

刚开始发现问题时,我们以为是带宽不够,后来把带宽加到绰绰有余,问题依旧。当时还以为是阿里云的问题——带宽没加上去,联系了客服,确认带宽的确加上了。
确认不是带宽的原因后,我们又从磁盘IO入手——图片站点的特点之一就是读磁盘很频繁。但从监测数据看,磁盘IO也在正常范围(更新:后来分析了一下,当时的Avg.Disk Read Queue Length在2左右,这个值对于图片站点这样的应用已经很高,因为图片站点的操作就是将文件内容读出来返回给浏览器,Disk Read Queue Length的值只要一高,就会对响应速度有明显影响。所以这个问题的根本原因还是当时云服务器所在的集群的磁盘IO高。我们采用负载均衡之后,Avg.Disk Read Queue Length一般在0.000)。
对于图片这样的静态文件站点,影响速度的两个最主要的因素(带宽与磁盘IO)都正常,CPU、内存占用也正常(静态文件站点本来对CPU与内存的资源需求就很小),而访问速度却奇慢,真是一个诡异的问题。
出现问题时,IIS的同时连接在3500左右,这个连接数应该是小意思。以前用自己的服务器,不是静态文件的站点,2万的同时连接数都撑得住。
一直忙到下班时间,都没解决问题。。。。
下班时间之后(访问量降下来了),突然恢复了正常,查看了IIS同时连接数,降到了2000以下。
问题肯定与云服务器的负载有关,负载达到一定程度(我们目前可观察到的指标是IIS同时连接数超过2000),云服务器就会有强烈反应(我们遇到的站点响应速度奇慢就是反应之一)。不管怎么样,这么强烈的反应肯定与对某一个资源的需求得不到及时满足有关,而资源无非就是CPU、内存、硬盘、网卡,前面三个资源通过监测都确认正常,网卡出问题的可能性很小,我们也不知道如何监测。每个部分都是正常的,整体却有问题。诡异问题不是徒有虚名。
对问题的原因我们束手无策,但我们又必须要解决问题,怎么办?
把当前问题(在某种情况下单台云服务器撑不住2000以上的并发连接)当作一个约束条件,在这个约束之下解决真正要解决的问题——让 image.cnblogs.com 恢复正常速度访问。
一下子问题变得简单了,既然单台云服务器撑不住2000以上的并发连接,那就分而治之,将请求分在多台云服务器上,让单台云服务器承受2000以下的并发边接。这样还会带来一个额外的好处,将带宽分在多台云服务器上购买,成本更低。(再次证明了明确真正要解决的问题,问题就解决了一半)
但是这种解决方法引发了另外一个问题,如何分而治之?负载均衡当然是首选,但是阿里云有且只有1个负载均衡器,已经用在了访问量更大的站点上。问题又变成了——如何不用负载均衡器做负载均衡?这时需要跳出当前的视野,来到用户发起请求的第一站——DNS服务器,通过DNS轮询达到负载均衡的效果。在DNS服务器中为 images.cnblogs.com 添加多个IP,每次解析时随机选取一个IP(虽然不是很均衡,但能够解决实际问题)。
今天我们就采用了“DNS轮询+两台云服务器”来验证我们的解决思路,效果很明显,images.cnblogs.com图片加载速度明显提升。为了达到更满意的效果,我们正在增加更多的云服务器。
明确真正要解决的问题、分而治之、跳出当前的视野,这就是我们在这次解决问题中想要分享的。
这里再简单描述一下这个问题:我们的图片站点(静态文件)迁移至云服务器后,在IIS并发连接数达到3500左右的时候,出现了响应速度奇慢的问题。后来,通过多台云服务器分流,将每台云服务器的IIS并发连接降至2000以下,问题得到解决。
也许这只是某种特殊情况下的偶发问题,但问题持续了一个工作日,背后肯定有它潜在的原因。对于云平台这样复杂的、承载客户关键业务的系统,任何一个响应速度奇慢的问题都值得重视。虽然现在还没引起阿里云的足够重视,但是我们会继续研究。
与阿里云客服沟通下来,他们始终以“他们没有对IIS的并发连接进行限制”为理由,怀疑问题出在IIS。
而我们却有不同的想法:
1、同样的站点、同样的IIS设置之前在我们自己的服务器上运行多年,从没出现这样的问题。——直接证明IIS设置没问题
2、我们在IIS设置的最大并发连接数限制是5000,出现问题时,发连接数只有3500左右。——与IIS的并发连接数限制无关
3、3500的并发连接对IIS来说是小菜一碟,而且这里是静态文件,更加是小小菜。我们以前用自己的服务器,在单台服务器上不仅一个ASP.NET站点支撑2万并发连接没问题,而且这台服务器同时正常跑着同样的图片站点。——与IIS的处理能力无关
4、如果是IIS的原因,会有一个很直接的表现,通过性能监视器监测当前站点的当前连接数(Current Connections),会看到连接数不断增加。根据我们的观察,出现这个问题时,这个值在3500左右波动,并没有不断增加。——监测数据反映IIS在正常工作
根据我们的分析,我们没有找到一条可以把问题归罪于IIS的理由,再加上磁盘IO正常、带宽充足。如果只置身于云服务器中,你根本感觉不到有问题存在,一切都正常运转,世界很美好。
但是,这是一个虚拟的世界,支撑这个虚拟世界的背后是虚拟化平台。我们的猜想就从这个点出发。
当浏览器发出一个图片请求时,请求会先到达虚拟化平台,经过虚拟化平台到达云服务器的IIS,IIS收到这个正常的请求后作出正常的响应,将图片内容发向请求端,到这里一切都正常(可以通过云服务器的监测数据看出)。
但是,响应内容不是由云服务器的IIS直接发向浏览器,而是经由虚拟化平台处理。也就是在客户浏览器与云服务器的IIS之间横亘着虚拟化平台,如果云服务器中一切正常,客户浏览器得到的响应却极不正常,那会不会可能是虚拟化平台的某个处理环节出现问题了呢?。。。
这就是我们的猜想,也只能猜想。猜想也是一种对问题的思考,每个问题只要认真对待,总会有收获。
希望这只是一次特殊情况下的偶发现象,也希望阿里云能重视这个问题,排除可能的潜在原因。
三、20130314云服务器故障经过
故障的原因是云服务器所在的集群负载过高,磁盘写入性能急剧下降,造成很多数据库写入操作超时。后来恢复正常的解决方法是将云服务器迁移至另一个集群。
下面是故障发生的主要经过:
今天上午9:15左右一位园友通过邮件反馈在访问园子时遇到502 Bad Gateway错误,见下图:
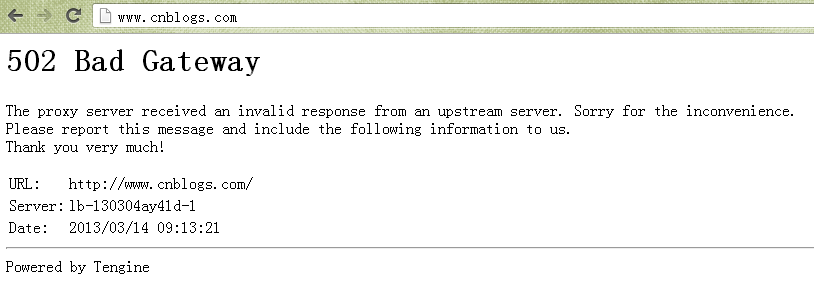
这是由阿里云负载均衡器返回的错误,Tegine是由阿里巴巴开发的开源Web服务器。我们猜测阿里云提供的负载均衡服务可能是通过Tegine反向代理实现的。
这个错误页面表示负载均衡器检测到负载均衡中的云服务器返回了无效的响应,比如500系列错误。
我们将这个情况通过工单反馈给了阿里云,得到的处理反馈是继续观察,可能是这位用户的网络线路的临时问题导致。
由于我们在这个时间段没遇到这个问题,也没有其他用户反馈这个问题,我们也认可了继续观察的处理方式。
(根据我们后来的分析,出现502 Bad Gateway错误可能是集群出现了瞬时负载高的情况)
下午17:20左右,我们自己也遇到了502 Bad Gateway错误,持续了大约1-2分钟。见下图:
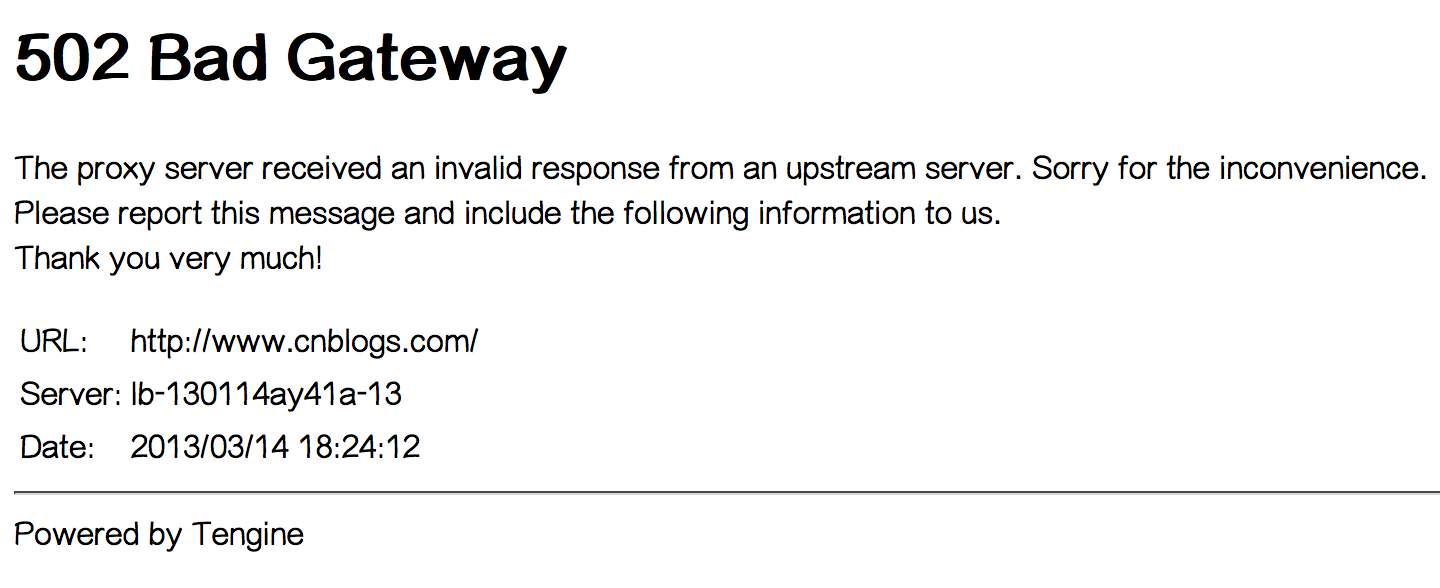
出问题期间,我们赶紧登录到两台云服务器查看情况,发现IIS并发连接数增长至原来的30多倍,而Bytes Send/sec为0,而且两台云服务器都是同样的情况。我们当时推断,这两台云服务器本身应该没有问题,问题可能出在它们与数据库服务器之间的网络通信。我们继续将这个情况通过工单反馈给阿里云。
刚把工单填好,我们就接到园友的电话反馈说博客后台不能发布文章,我们一测试,果然不能发布,报数据库超时错误,见下图:

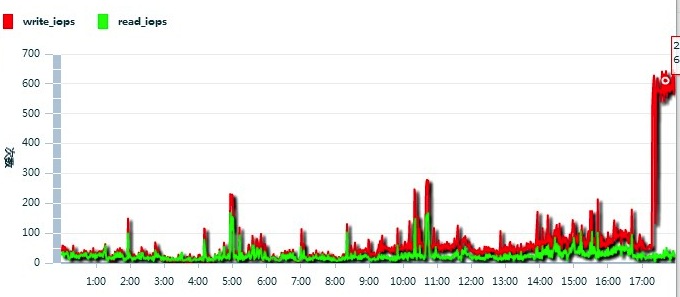
但打开现有的文章速度很快,也就是说读正常,写有问题。赶紧登录数据库服务器通过性能监视器查看磁盘IO情况,果然磁盘写入性能有问题,见下图:
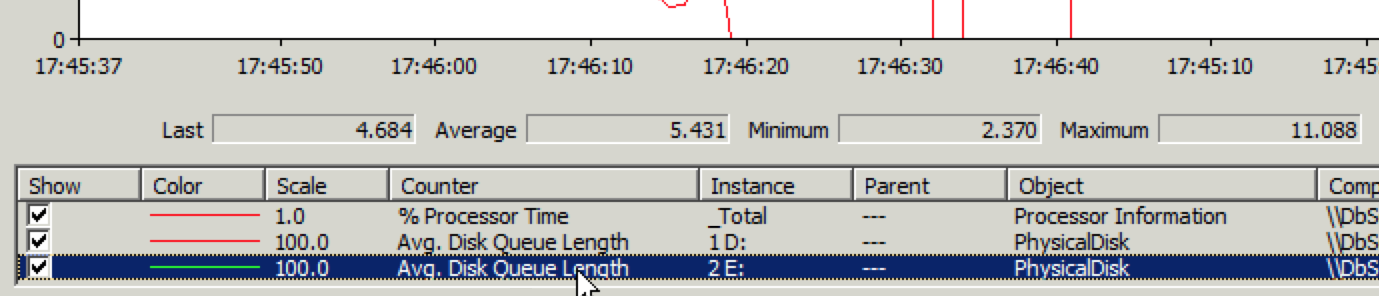
Avg. Disk Write Queue Length超过1就说明有问题了,现在平均已经到了4~5。进入阿里云网站上的管理控制台一看,磁盘IO问题就更明显了,见下图:
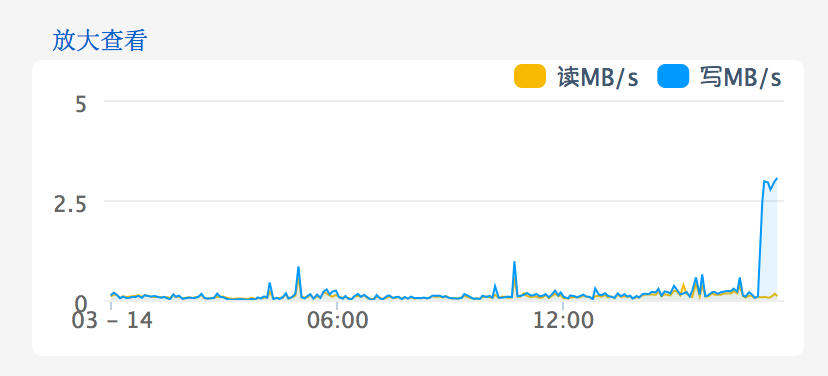
继续向阿里云反馈情况,得到的反馈是这台云服务器IOPS太高了,见下图:
于是,阿里云工作人员将这台云服务器迁移至另一个集群,问题立刻解决。
四、问题的根源——买到她的“人”,却买不到她的“心”
这里的“她”指的是硬盘,“她的人”指的是硬盘空间,“她的心”指的是硬盘的IO能力。
自从使用阿里云以来,我们遇到了三次故障,这三次故障都与磁盘IO高有关。第一次故障发生在跑zzk.cnblogs.com索引服务的云服务器上,当时的Avg.Disk Read Queue Length高达200多;第二次故障发生在跑images.cnblogs.com静态文件的云服务器上,当时的Avg.Disk Read Queue Length在2左右(后来分析,对于图片站点这样的直接读文件进行响应的应用,Disk Read Queue Length达到这个值会明显影响响应速度);第三次故障发生在跑数据库服务的云服务器上,当时的Avg. Disk Write Queue Length达到4~5,造成很多的数据库写入操作超时。
(这里既提到“硬盘”,又提到“磁盘”,我们这样界定的:在云服务器中看到的硬盘叫磁盘[虚拟出来的硬盘],在集群中的物理硬盘叫硬盘)
这三次的磁盘IO高都不是我们云服务器内的应用引起的,最直接的证据就是将云服务迁移至另一个集群之后,问题立即解决。也就是说云服务器的磁盘IO高是因为它所在的集群的硬盘IO高。集群的硬盘IO是集群内所有云服务器的磁盘IO的累加,集群的硬盘IO高是因为集群中某些云服务器的磁盘IO过高。而我们自己的云服务器内的应用产生的磁盘IO在正常范围,问题出在其他用户的云服务器产生过多的磁盘IO,造成整个集群硬盘IO高,从而影响了我们。
为什么其他云服务器引起的硬盘IO问题会影响到我们?问题的根源就在于集群的硬盘IO被集群中的所有云服务器所共享,而且这种共享没有被有效的限制、没有被有效的隔离,大家都在争抢这个资源,同时争抢的人太多,就会排长多。而且对于每个云服务器来说,也不知道有多少台云服务器在争抢,从云服务器使用者的角度根本无法躲开这个争抢;就像在世博会期间,你起再早去排队,也得排超长的队。如果每个云服务器使用的硬盘IO资源是被限制或隔离的,其他云服务器产生再多的磁盘IO也不会影响到我们的云服务器;就像在一个小区,你一个人租了一套房子,其他的一套房子即使住了100人,也不会影响到你。
你可以买到CPU、内存、带宽、硬盘空间,你却买不到一心一意为你服务的硬盘IO,这就是当前阿里云虚拟化平台设计时未考虑到的一个重要问题。
经过与阿里云技术人员的沟通,得知他们已经意识到这个问题,希望这个问题能早日得到解决。
资料链接
[1].云计算之路:遭遇奇怪的云服务器问题:http://www.cnblogs.com/cmt/archive/2013/03/07/2948211.html
[2].云计算之路-入阿里云后:解决images.cnblogs.com响应速度慢的诡异问题:http://www.cnblogs.com/cmt/archive/2013/03/12/2955405.html
[3].云计算之路-入阿里云后:对云服务器并发连接问题的猜想:http://www.cnblogs.com/cmt/archive/2013/03/13/2957583.html
[4].云计算之路-迁入阿里云后:20130314云服务器故障经过:http://www.cnblogs.com/cmt/archive/2013/03/14/2960583.html
[5].云计算之路-迁入阿里云后:问题的根源——买到她的“人”,却买不到她的“心”:http://www.cnblogs.com/cmt/archive/2013/03/15/2961145.html
评论: 0 | 引用: 0 | 查看次数: 4789
发表评论
请登录后再发表评论!

