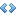 程序代码
程序代码
不错呦!smile@林凯西,确保“准备文件”中的几个文件都有安装,S...您好,看了您这篇帖子觉得很有帮助。但是有个问题想请...我的修改过了怎么还被恶意注册呢 @jjjjiiii 用PJ快9年了,主要是A...PJ3啊,貌似很少有人用PJ了,现在不是WP就是z...@332347365,我当时接入时错误码没有-10...楼主,ChkValue值应为-103是什么意思呢?...大哥 你最近能看到我发的信息,请跟我联系,我有个制...
 .NET中使用Newtonsoft.Json进行序列化
.NET中使用Newtonsoft.Json进行序列化
编辑:dnawo 日期:2009-06-08
Effective C# 原则10: 明白GetHashCode()的缺陷
编辑:dnawo 日期:2009-06-08
这是本书中唯一一个被一整个函数占用的原则,你应该避免写这样的函数。GetHashCode()仅在一种情况下使用:那就是对象被用于基于散列的集合的关键词,如经典的HashTable或者Dictionary容器。这很不错,由于在基类上实现的GetHashCode()存在大量的问题。对于引用类型,它可以工作,但高效不高;对于值类型,基类的实现经常出错。这更糟糕。你自己完全可以写一个即高效又正确的GetHashCode()。没有那个单一的函数比GetHashCode()讨论的更多,且令人困惑。往下看,为你解释困惑。
如果你定义了一个类型,而且你决不准备把它用于某个容器的关键词,那就没什么事了。像窗体控件,网页控件,或者数据库链接这样的类型是不怎像要做为某个任何的关键词的。在这些情况下,什么都不用做了。所有的引用类型都会得到一个正确的散列值,即使这样效率很糟糕。值类型应该是恒定的(参见原则7),这种情况下,默认的实现总是工作的,尽管这样的效率也是很糟糕的。在大多数情况下,你最好完全避免在类型的实例上使用GetHashCode()。
然而,在某天你创建了一个要做为HashTable的关键词来使用的类型,那么你就须要重写你自己的GetHashCode()的实现了。继续看,基于散列(算法)的集合用散列值来优化查找。每一个对象产生一个整型的散列值,而该对象就存储在基于这个散列值的“桶”中。为了查找某个对象,你通过它的散列值来找到这个(存储了实际对象的)“桶”。在.Net里,每一对象都有一个散列值,它是由System.Object.GetHashCode()断定的。任何对GetHashCode()的重写都必须遵守下面的三个规则:
如果你定义了一个类型,而且你决不准备把它用于某个容器的关键词,那就没什么事了。像窗体控件,网页控件,或者数据库链接这样的类型是不怎像要做为某个任何的关键词的。在这些情况下,什么都不用做了。所有的引用类型都会得到一个正确的散列值,即使这样效率很糟糕。值类型应该是恒定的(参见原则7),这种情况下,默认的实现总是工作的,尽管这样的效率也是很糟糕的。在大多数情况下,你最好完全避免在类型的实例上使用GetHashCode()。
然而,在某天你创建了一个要做为HashTable的关键词来使用的类型,那么你就须要重写你自己的GetHashCode()的实现了。继续看,基于散列(算法)的集合用散列值来优化查找。每一个对象产生一个整型的散列值,而该对象就存储在基于这个散列值的“桶”中。为了查找某个对象,你通过它的散列值来找到这个(存储了实际对象的)“桶”。在.Net里,每一对象都有一个散列值,它是由System.Object.GetHashCode()断定的。任何对GetHashCode()的重写都必须遵守下面的三个规则:

