


 上一篇:
上一篇:  下一篇:
下一篇:  文章来自:
文章来自:  Tags:
Tags:  最新日志:
最新日志:
不错呦!smile@林凯西,确保“准备文件”中的几个文件都有安装,S...您好,看了您这篇帖子觉得很有帮助。但是有个问题想请...我的修改过了怎么还被恶意注册呢 @jjjjiiii 用PJ快9年了,主要是A...PJ3啊,貌似很少有人用PJ了,现在不是WP就是z...@332347365,我当时接入时错误码没有-10...楼主,ChkValue值应为-103是什么意思呢?...大哥 你最近能看到我发的信息,请跟我联系,我有个制...
别再乱加 try-catch 了!7 个异常处理策略,让你的程序再也不崩溃
编辑:dnawo 日期:2026-05-12

写代码最头疼的事之一,就是处理各种莫名其妙的错误。很多人要么图省事,整个程序套一个大 try-catch,一出错全崩;要么走另一个极端,每一行代码都加一个 try-catch,结果一个地方错了,后面跟着报一堆连锁错误,越修越乱。今天我们从一个简单的例子开始,由浅入深讲透 7 个工业界最实用的异常处理策略。学会这些,你写的程序会比别人的健壮 10 倍。
假设你写了一个简单的计算程序,用户输入四个数字 a、b、c、d,程序做三件事:
 引用内容
引用内容a + b = e
e + 2 = f
c + d = g
e + 2 = f
c + d = g
一开始你可能这么写:
复制内容到剪贴板 程序代码
程序代码
程序代码// 坑1:全局大try-catch
try
{
int e = a + b;
int f = e + 2;
int g = c + d;
}
catch
{
Console.WriteLine("计算出错了!");
}
try
{
int e = a + b;
int f = e + 2;
int g = c + d;
}
catch
{
Console.WriteLine("计算出错了!");
}
结果发现,只要 a+b 输错了(比如输了个字母),整个程序直接退出,连本来能正常算的 c+d 也跑不了。然后你又改成这样:
复制内容到剪贴板 程序代码
程序代码// 坑2:每行一个try-catch
int e, f, g;
try
{
e = a + b;
}
catch
{
Console.WriteLine("a+b 出错了!");
}
try
{
f = e + 2; // e 没赋值成功,这里继续报错
}
catch
{
Console.WriteLine("e+2 出错了!");
}
try
{
g = c + d;
}
catch
{
Console.WriteLine("c+d 出错了!");
}
int e, f, g;
try
{
e = a + b;
}
catch
{
Console.WriteLine("a+b 出错了!");
}
try
{
f = e + 2; // e 没赋值成功,这里继续报错
}
catch
{
Console.WriteLine("e+2 出错了!");
}
try
{
g = c + d;
}
catch
{
Console.WriteLine("c+d 出错了!");
}
更糟了!a+b 出错后,e 不存在,e+2 那行必然又报一个错,一个错误变成两个,日志里全是没用的垃圾信息。这时候你想到了一个绝妙的办法:把有依赖关系的步骤放一起,没依赖的分开:
复制内容到剪贴板 程序代码
程序代码// 正确的做法
int e, f, g;
// 第一组:有依赖关系的步骤放一起
try
{
e = a + b;
f = e + 2;
}
catch
{
Console.WriteLine("f 值计算出错!");
}
// 第二组:独立无依赖,单独捕获
try
{
g = c + d;
}
catch
{
Console.WriteLine("g 值计算出错!");
}
int e, f, g;
// 第一组:有依赖关系的步骤放一起
try
{
e = a + b;
f = e + 2;
}
catch
{
Console.WriteLine("f 值计算出错!");
}
// 第二组:独立无依赖,单独捕获
try
{
g = c + d;
}
catch
{
Console.WriteLine("g 值计算出错!");
}
完美!a+b 出错只会影响 f 的计算,g 照样能正常出来。这就是我们今天要讲的第一个,也是最基础最重要的异常处理策略。
策略 1:依赖任务组隔离式 —— 把错误关在小房间里
这是所有异常处理的基石,核心思想就一句话:谁和谁有关系,就把他们关在同一个房间里;没关系的,就分开关。
关键设计要点
● 有依赖关系的步骤(a+b 和 e+2,后者必须等前者算完),必须放在同一个 try-catch 里。一个错了,整个房间的门就关上,后面的步骤不再执行。
● 没有任何关系的步骤(算 f 和算 g),必须放在不同的 try-catch 里。一个房间着火了,不会烧到另一个房间。
我们把这样一个 "房间" 叫做一个任务组。每个任务组是一个最小的错误隔离单元,组内错误终止本组,组间错误互不影响。
✅适用场景:所有程序,不管大小,第一步都应该先做这个。这是从 "写能跑的代码" 到 "写健壮的代码" 的第一道门槛。
策略 2:重试模式 —— 给错误一次改过自新的机会
依赖任务组隔离解决了 "错误乱跑" 的问题,但还有一个问题:很多错误其实是暂时的。
比如你写了一个程序,需要从网上拉取数据然后计算。有时候网络抖了一下,请求失败了,其实等 1 秒钟再试一次就好了。如果直接标记任务失败,就太可惜了。
这就是重试模式:对于那些 "可能自己好" 的错误,不要立刻放弃,自动重试几次。
关键设计要点
● 只重试 "瞬时错误":网络超时、连接失败、服务器临时 503 这些。参数错误、权限不足这种重试 100 次也没用的,绝对不要重试。
● 重试次数不要太多:2-3 次足够了,多了会拖慢系统。
● 重试间隔要递增:第一次等 1 秒,第二次等 2 秒,第三次等 4 秒,避免大家同时重试把服务器压垮。
✅适用场景:所有涉及网络调用、数据库查询、文件读写的地方,都应该加上重试。生产环境里 80% 的错误都是这种瞬时故障。
策略 3:降级模式 —— 丢车保帅,保证核心能用
有些任务就算失败了,天也塌不下来。
比如你做一个电商网站,商品详情页有 "商品价格" 和 "猜你喜欢" 两个部分。如果 "猜你喜欢" 的服务挂了,难道要让整个商品页都打不开吗?当然不行。
这时候就用降级模式:非核心任务失败时,不返回错误,而是返回一个预设的默认值,保证核心功能正常运行。"猜你喜欢" 挂了,就显示 "暂无推荐";统计计数失败了,就记个 0,不影响用户下单;头像加载失败了,就显示一个默认头像。
关键设计要点
● 一定要分清楚核心和非核心。核心功能绝对不能降级,比如支付、下单。
● 降级结果要安全,不能返回会导致后续逻辑崩溃的值。
✅适用场景:所有非核心的辅助功能,都可以设计降级策略。用户可能根本没注意到某个小功能没了,但如果整个页面崩了,他一定会走。
策略 4:舱壁模式 —— 别让一个慢任务拖垮整个系统
前面三个策略都是隔离 "错误",但还有一种更隐蔽的杀手:慢任务。
比如你有一个程序,同时跑 10 个任务组。其中一个任务组陷入了死循环,或者调用了一个特别慢的接口,占满了所有 CPU 和线程。结果其他 9 个正常的任务组也得不到资源,跟着一起卡死。
这就像轮船的水密隔舱,如果没有隔舱,一个地方漏水,整条船都会沉。舱壁模式就是给每个任务组分配独立的资源,一个任务组炸了,只会用光自己的资源,不会影响别人。
这时候就用舱壁模式:别让一个慢任务拖垮整个系统。原来 10 个任务共用 100 个线程,现在给每个任务分 10 个线程。就算一个任务把自己的 10 个线程全占满了,还有 90 个线程给其他 9 个任务用。
✅适用场景:多任务并发执行的系统,特别是包含不可信第三方调用的系统。
策略 5:熔断器模式 —— 及时止损,防止雪崩
想象一下,你调用的一个第三方服务彻底挂了。这时候如果还有源源不断的请求过来,每个请求都要等 30 秒才超时,很快你的服务器的所有线程都会被这些等待的请求占满,导致你的整个服务也挂了。这就是雪崩效应:一个服务的故障,层层传导,最终导致整个系统崩溃。
熔断器模式就是解决这个问题的,它就像家里的保险丝:
● 正常情况:保险丝闭合,电流正常通过
● 故障情况:当失败次数超过阈值,保险丝断开,直接切断电流
● 恢复情况:过一段时间,保险丝尝试半开,放少量电流过去试试,如果好了就重新闭合
放到程序里就是:当某个任务组的失败率超过 50%,就暂时停止执行这个任务组,直接返回降级结果。等过几分钟,再尝试几次,如果服务恢复了,就继续正常执行。
✅适用场景:高并发系统中,所有依赖外部服务的地方。这是防止系统雪崩的最后一道防线。
策略 6:补偿事务模式 —— 做错了,就想办法改回来
前面的策略都是 "出错了怎么办",但还有一种更复杂的情况:一个业务流程需要多个步骤依次完成,前几个成功了,后面的失败了。
比如下单流程:扣减库存 → 创建订单 → 扣减余额。如果扣减库存和创建订单都成功了,扣减余额失败了怎么办?总不能让用户没付钱就拿到货吧。
这时候就需要补偿事务模式:把每个步骤都配上一个 "撤销操作"。如果后面的步骤失败了,就依次执行前面步骤的撤销操作,把系统恢复到原来的状态。
● 扣减库存的撤销操作:增加库存
● 创建订单的撤销操作:取消订单
✅适用场景:跨多个服务、多个数据库的业务流程,比如订单、支付、转账。
策略 7:冗余容错模式 —— 鸡蛋不要放在一个篮子里
最后这个策略,已经超出了单台机器代码的范畴,是系统级别的容错。
前面所有的策略,都解决不了一个问题:服务器宕机了。不管你代码写得多好,机器突然断电了,程序还是跑不了。
这时候就需要冗余容错模式:多准备几台机器,同时跑一样的程序。一台挂了,其他的还能继续工作。
● 主备模式:一台主机器干活,一台备机器待命,主的挂了备的顶上
● 集群模式:多台机器一起干活,通过负载均衡分发请求
● 多活模式:多个城市的数据中心同时提供服务,一个城市地震了,其他城市还能用
✅适用场景:对可用性要求极高的系统,比如银行、电商、微信、支付宝。
总结
没有最好的策略,只有最合适的。根据不同的场景,从简单到复杂叠加就好:
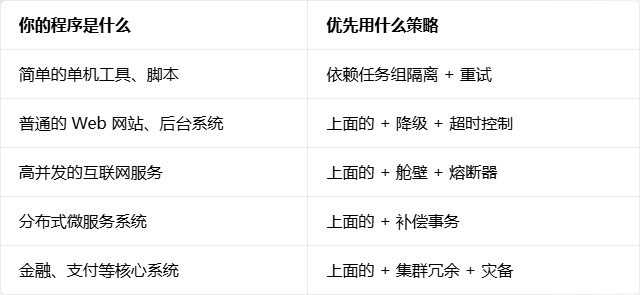
很多新手觉得异常处理是 "边角料",是写完核心逻辑后随便加的东西。但实际上,一个程序 90% 的代码,都是在处理各种异常情况。
真正的好代码,不是永远不出错的代码,而是出错了能精准控制影响范围、能自己恢复、能快速定位问题的代码。
从今天开始,扔掉你的全局大 try-catch,也不要再每行代码都加 try-catch。先从划分依赖任务组开始,一步一步把这些策略用起来,你会发现你的程序会变得越来越稳。
相关链接
[1].与豆包互动原文:https://www.mzwu.com/doc/try-catch.pdf
评论: 0 | 引用: 0 | 查看次数: 253
发表评论
请登录后再发表评论!

