 程序代码
程序代码
不错呦!smile@林凯西,确保“准备文件”中的几个文件都有安装,S...您好,看了您这篇帖子觉得很有帮助。但是有个问题想请...我的修改过了怎么还被恶意注册呢 @jjjjiiii 用PJ快9年了,主要是A...PJ3啊,貌似很少有人用PJ了,现在不是WP就是z...@332347365,我当时接入时错误码没有-10...楼主,ChkValue值应为-103是什么意思呢?...大哥 你最近能看到我发的信息,请跟我联系,我有个制...
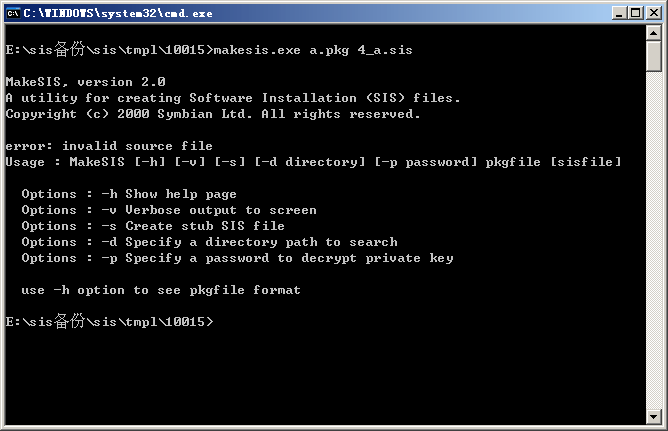
 pkg文件名为单个字符时makesis无法成功打包sis
pkg文件名为单个字符时makesis无法成功打包sis
编辑:dnawo 日期:2008-09-02
 .NET自定义分页控件PageNavigator v1.0(源码)
.NET自定义分页控件PageNavigator v1.0(源码)
编辑:dnawo 日期:2008-09-02
让.Net程序脱离.NET Framework框架运行的几种方法
编辑:dnawo 日期:2008-09-02
在.Net Framework下,你就算写一个小小的控制台程序,哪怕只有几K大小,我们必须要安装一个几十M的Framework Runtime,所以许多人在寻找让.NET程序脱离.Net Framework运行的方法,下面我们说说几种常见的方法:
1.使用飞信的.NET虚拟环境
安装完"飞信2008正式版"后,在其安装文件夹下有个VMDotNet子文件夹,里面就是.NET虚拟环境相关文件了,我们可以使用"VMDotNet\v2.0.50727\FetionVM.exe"来启动运行我们的.NET WinForm程序:
1.使用飞信的.NET虚拟环境
安装完"飞信2008正式版"后,在其安装文件夹下有个VMDotNet子文件夹,里面就是.NET虚拟环境相关文件了,我们可以使用"VMDotNet\v2.0.50727\FetionVM.exe"来启动运行我们的.NET WinForm程序:
 批处理检测是否安装.NET Framework
批处理检测是否安装.NET Framework
编辑:dnawo 日期:2008-09-01
还是没习惯使用left join
编辑:dnawo 日期:2008-09-01
C#生成彩色验证码
编辑:dnawo 日期:2008-08-31
table变量 VS 临时表
编辑:dnawo 日期:2008-08-31
SQL语句union关键字使用
编辑:dnawo 日期:2008-08-31
将一张表的数据更新到另一张表
编辑:dnawo 日期:2008-08-30
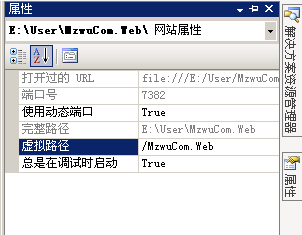
解决VS2008使用文件系统建立的网站在浏览器中查看时路径问题
编辑:dnawo 日期:2008-08-29
使用VS2008在"E:\User\MzwuCom.Web"下建立了一个站点,在浏览器中查看时你会发现路径类似于"http://localhost:7382/MzwuCom.Web/Default.aspx",而不是"http://localhost:7382/Default.aspx",这样整个站点就变成了在一个虚拟目录下,这在执行某些操作时会出现问题,例如打开站点根目录下一个文件Server.MapPath("/test.txt"),所以必须去掉虚拟目录,设置方法:打开网站属性窗口,将虚拟路径"/MzwuCom.Web"设置为"/"即可。